Health Checks Explained
How Load Balancers Detect and Remove Failed Servers

1. Problem Statement
Imagine your application is running on multiple servers behind a load balancer.
Now one server crashes.
But the load balancer doesn’t know it yet.
What happens?
Traffic still gets sent to that failed server
Users start seeing errors (timeouts / 5xx)
Your system looks up, but users experience failure
Real-world impact
Think of an e-commerce site during a sale:
3 servers running
1 crashes silently
33% of users now hit a dead server
That’s lost revenue, poor experience, and frustrated users.
2. Concept Explanation
What are Health Checks?
Health checks are automated probes sent by a load balancer to verify if a server is alive and working correctly.
They answer a simple question:
“Should I send traffic to this server or not?”
Why Load Balancer Needs Them
Without health checks:
Load balancer assumes all servers are healthy
Sends traffic blindly
Failures propagate to users
With health checks:
Only healthy servers receive traffic
Failed servers are automatically removed
Simple Analogy
Think of a doctor monitoring patients in ICU:
Regular heartbeat checks
If heartbeat stops → alert + action
Patient is taken off active rotation
Load balancer does the same:
Periodically checks servers
Removes unhealthy ones
Adds them back after recovery
3. Types / Variations
1. TCP Health Check
Checks if port is open
Example: Can I connect to port 80?
✔ Fast
❌ Doesn’t verify application health
2. HTTP Health Check
Sends HTTP request (e.g.,
/health)Expects valid response (200 OK)
✔ Verifies application is working
❌ Slightly slower than TCP
3. Passive vs Active Checks
Active Health Checks
Load balancer sends periodic probes
Independent of user traffic
Passive Health Checks
Observes real traffic
Marks server down on failures
Most systems use both together
4. How It Works Internally
Here’s what happens behind the scenes:
Load balancer sends periodic checks
Server responds (success or failure)
LB tracks response history
Applies threshold logic
This allows the load balancer to make decisions without waiting for user failures.
Key Logic
Interval → How often checks are sent
Timeout → Max wait for response
Failure Threshold → After N failures → mark DOWN
Success Threshold → After N successes → mark UP
Decision Flow
If healthy → keep sending traffic
If failed → stop routing traffic
If recovered → add back to pool
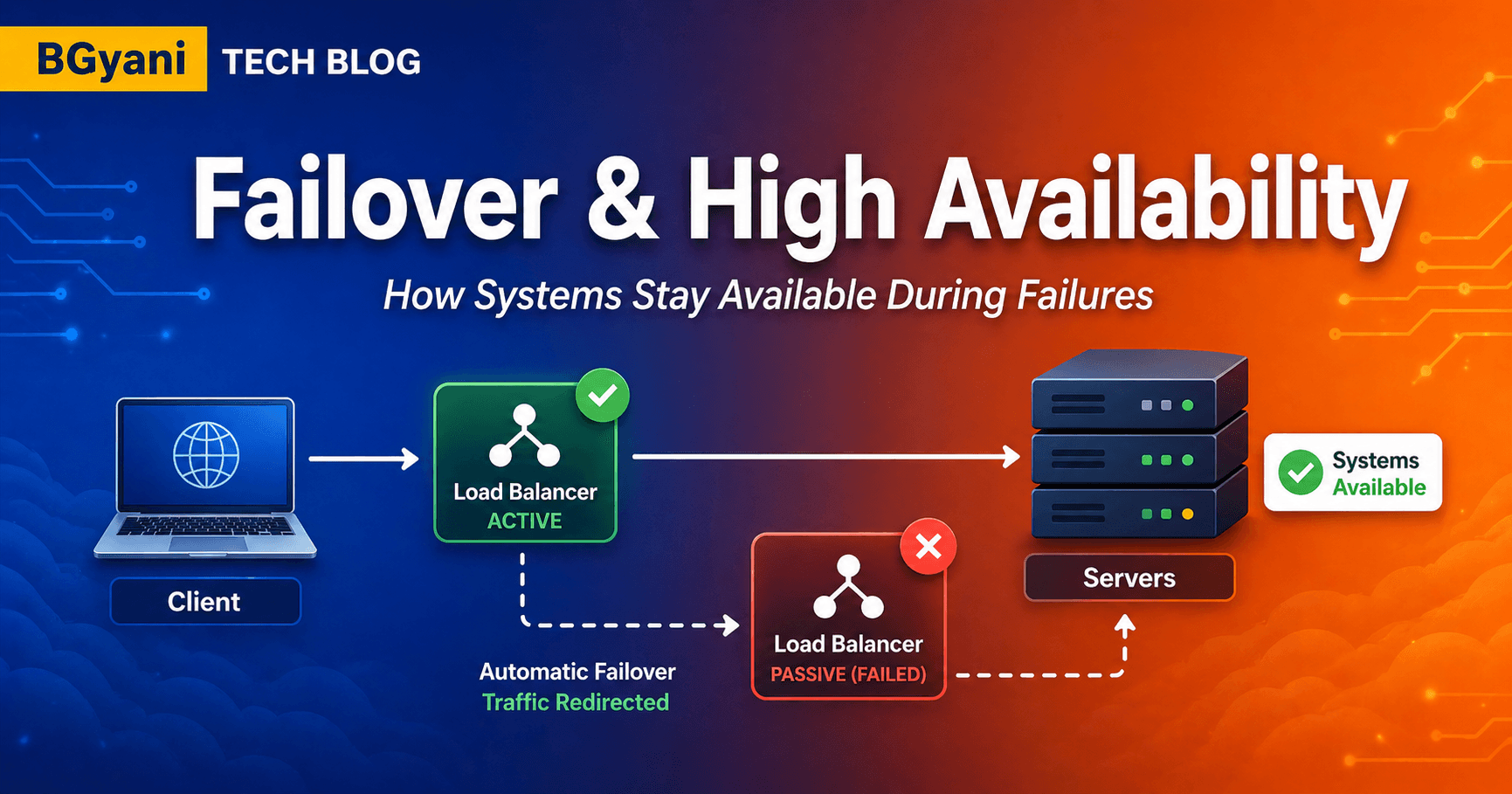
5. Diagram

Figure: health check flow loadbalancer.png
Flow shows:
Client → Load Balancer → Servers
Health probes from LB
One server healthy (green)
One server failed (red)
Traffic routed only to healthy server
The load balancer continuously probes servers and routes traffic only to those marked healthy.
6. Real-World Example
E-commerce Sale Scenario
Traffic spike during sale
3 backend servers
One crashes due to overload
Without health checks:
- Users hit failed server → errors
With health checks:
LB detects failure quickly
Removes server from rotation
Traffic continues smoothly on remaining servers
7. Common Issues / Pitfalls
1. Wrong Health Check Path
/healthendpoint misconfiguredAlways returns failure
2. Slow Response Misinterpreted
App is slow, not dead
Timeout too aggressive → false failures
3. Flapping (Frequent UP/DOWN)
Threshold too low
Servers keep toggling
4. Overly Aggressive Checks
Very frequent checks
Adds unnecessary load
8. Try It Yourself (MANDATORY)
Try it yourself 👇
9. Key Takeaways
Health checks ensure only healthy servers receive traffic
They prevent silent failures impacting users
HTTP checks provide deeper validation than TCP
Threshold tuning is critical to avoid false positives
They enable self-healing systems
10. Conclusion
Health checks are the decision engine behind reliable load balancing.
Without them:
- Load balancing becomes blind distribution
With them:
- It becomes intelligent traffic routing
11. Series Continuity
In the previous blog, we understood how load balancers distribute traffic.
Now we’ve added intelligence:
Not just where to send traffic — but where NOT to send it
12. Final Thought
A system is not truly resilient unless it can:
Detect failure
React automatically
Recover gracefully
Health checks are the first step toward that resilience.
13. Practical: NetScaler Hands-on
13.1 Mini Lab
Create LB vServer
Add backend service
Enable HTTP health check
13.2 Variation / Experiment
Change interval (e.g., 5s → 1s)
Adjust timeout
Observe failover speed
13.3 Commands
- Check Load Balancer Status
# Check Load Balancer status
show lb vserver <vserver-name>
# Check backend service health
show service <service-name>
# View health monitor configuration
show lb monitor <monitor-name>
# Enable health monitoring
set service <service-name> -healthMonitor YES
# Tune health check behavior
set lb monitor <monitor-name> -interval 5 -resptimeout 3 -retries 3