How Load Balancer Health Checks Work in NetScaler
Understand How Load Balancers Identify Healthy and Failed Servers

1. The Problem: What Happens When a Server Fails?
Imagine you have multiple backend servers behind a load balancer. Everything works fine... until one server crashes. Now:
Users are still sent to that failed server
Some requests succeed, others fail
Your application feels "randomly broken"
From a user's perspective, this is worse than a full outage. This is exactly the problem health checks solve.
2. What Are Health Checks?
A health check is how a load balancer verifies whether a backend server is ready to handle traffic.
Instead of blindly forwarding requests, NetScaler:
Continuously checks each server
Marks it as UP or DOWN
Sends traffic only to healthy servers
Think of it like a quick "status check" before assigning work.
3. Types of Health Checks
L3 Health Check - ICMP (Ping)
Works at Network Layer (Layer 3)
Uses ICMP (Ping) to check reachability
Key Points:
Very fast: Ping request → Ping response.
Useful for basic reachability.
Does NOT validate application health
Note: A server can respond to ping even if the application is down.
L4 Health Checks - Basic Connectivity
Works at Transport layer (Layer 4) e.g. TCP level.
Checks: "Can I establish a connection?"
Key Points:
Fast and Lightweight
Cannot detect application issues
Example: TCP handshake success
L7 Health Checks - Application-Level
Works at Application Layer e.g. HTTP/HTTPS level
Checks: "Is the application working correctly"
Key Points:
Most reliable application status
Detects real application failures
Slightly more overhead
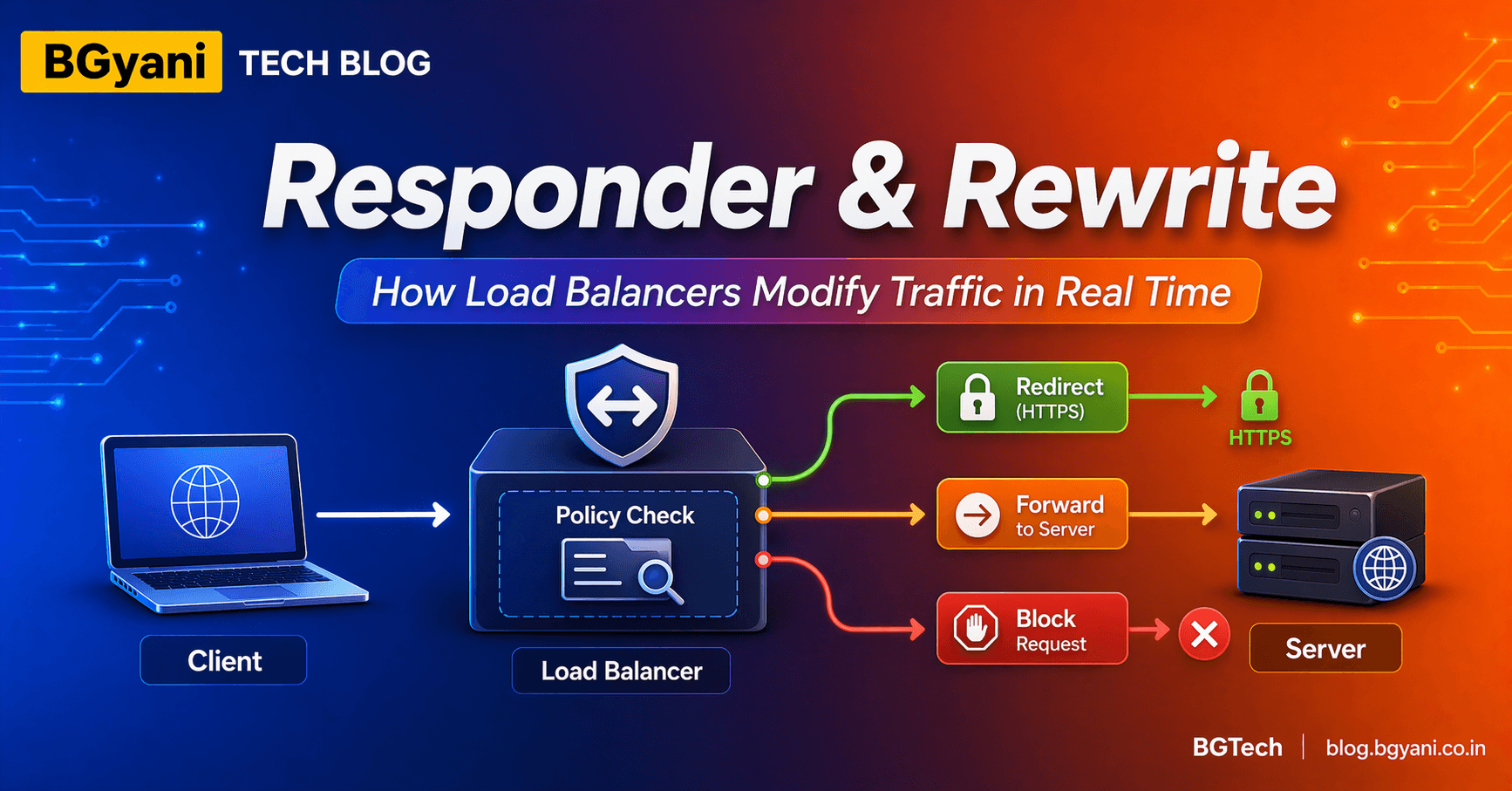
In most real-world scenarios, L7 checks are preferred. NetScaler ECV monitors not only check if the server is up, but also check if the requested content is present on the website. Example: HTTP GET /health → Expect 200 OK
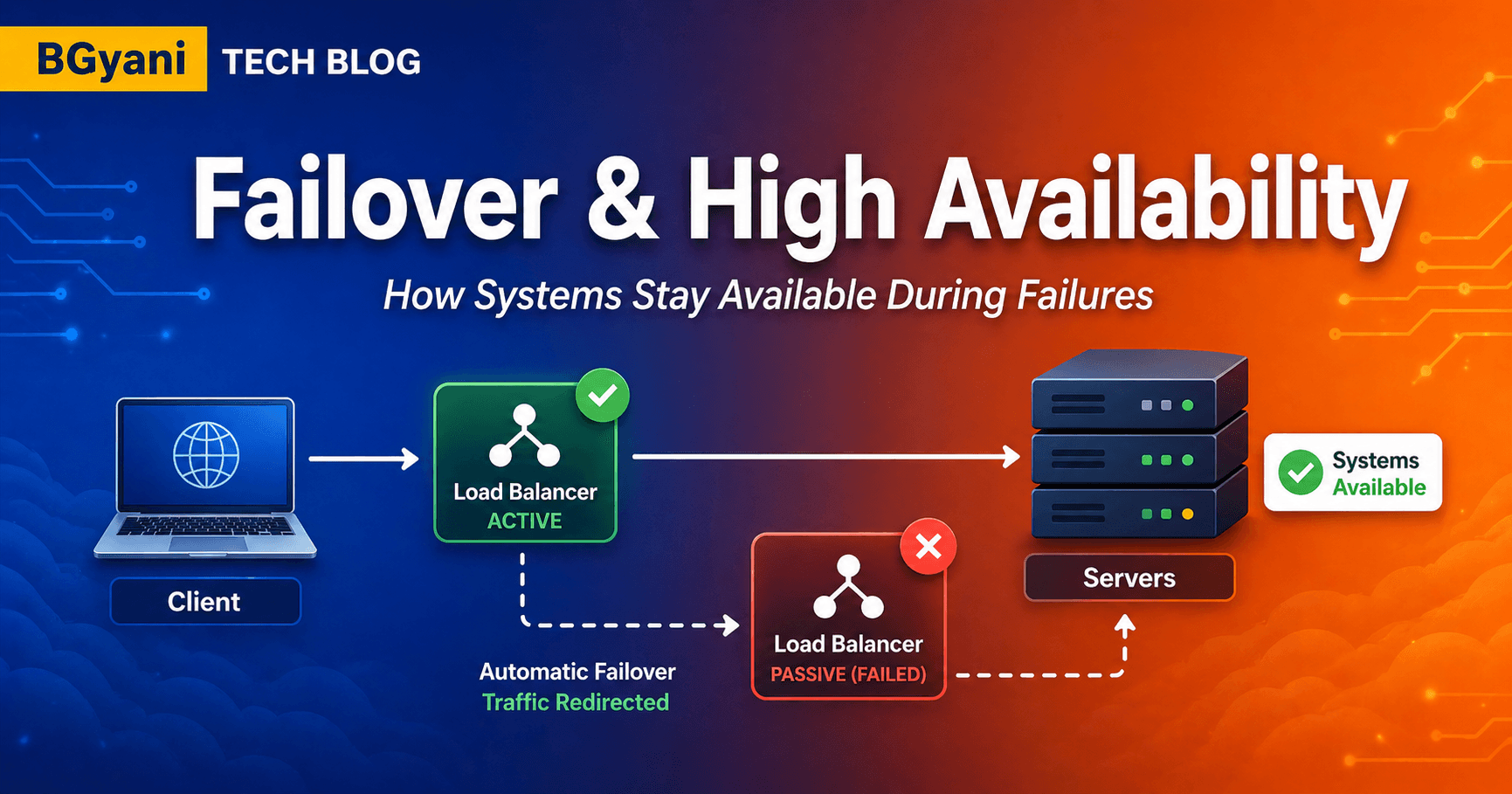
4. How Health Checks Work Internally
Here's what happens inside NetScaler:
Periodic probes are sent (e.g. every 5 seconds)
Backend servers respond
Based on response:
Success → marked UP
Failure → marked DOWN
- Traffic is routed to healthy servers
NetScaler also uses:
Failure Threshold &rarr failures before marking DOWN (failureretries)
Success Threshold &rarr successful checks before marking UP (successretries)
This prevents frequent UP/DOWN state changes (flapping).

Figure: netscaler-load-balancer-health-check-flow.png
5. Real-World Example
Let's take a simple e-commerce scenario:
Server is reachable (ping works)
TCP connection works
But the checkout service is down
With L3 and L4 checks:
Server still appears healthy
Users face failures
With L7 checks:
Checkout health fails
NetScaler removes server from pool
6. Common Issues
Using Only Ping Checks
Server responds to ping, but application is down. Always combine with L7 checks.
Wrong Health Check Endpoint
Checking instead of health. Use a dedicated health endpoint.
Very Frequent Checks
Too many probes overload servers. Keep interval balanced (5-10 sec).
Ignoring Timeouts
Slow responses may be marked as healthy. Configure proper timeout.
7. NetScaler Commands (Quick Reference)
If you are working with NetScaler, these commands help verify health checks in real environments.
Check Service Status
show service --summary
Sample Output Truncated
Service Name State IP Port Protocol
svc-web-1 UP 10.0.0.1 80 HTTP
svc-web-2 DOWN 10.0.0.2 80 HTTP
Check Bound Monitor
show service svc-web-1
Sample Output Tuncated
Monitor Name: http-monitor
State: UP
Last Response: HTTP 200 OK
Check Monitor Configuration
show lb monitor -summary
Sample Output Truncated
Name State Type
http-monitor ENABLED HTTP-ECV
Check Monitor Details
show lb monitor http-monitor
Sample Output Truncated
Name: http-monior TYPE: HTTP-ECV State: ENABLED
Interval: 5 sec Retries: 3
Response timeout: 2 sec
Special Paramters:
Send String: "GET /health"
Receive String: "200"
Mini Lab: Try This Yourself
- Run:
show service
Stop service on one backend server
Run again:
show service
Observe
- Server moves from UP → DOWN
4. Restart service → becomes UP again
Bonus Round:
Use only Ping monitor
Stop application
Server shows UP, but application is broken
Key learning: Reachability ≠ Application Health
What You Learned
Health checks are continuous
NetScaler dynamically adjusts traffic
L3 and L4 checks are limited
L7 checks provide real reliability
9. Conclusion
Health checks are one of the most critical components of load balancing.
They ensure:
Only healthy servers receive traffic
Failures are automatically isolated
Users get a consistent experience
Without proper health checks, load balancing becomes unreliable.
Continue Learning
If you're new to this series, start here: